Kubernetes is a great system for handling clusters of containers (whether on cloud or on-premise), but deploying and managing containerized applications for ML can be a challenging task.
Kubeflow is known as a machine learning toolkit for Kubernetes. It is an open source project used for making deployments of Machine Learning workflows on Kubernetes simple, portable, and scalable. It is used by data scientists and ML engineers who want to build, experiment, test and serve their ML workloads to various environments.
Some of the main components that make Kubeflow useful include:
- Central Dashboard, that provides access to the other main components through a Web UI,
- Notebook Servers, to set up Jupyter notebooks
- Katib, for automated tuning of ML model's hyperparameters
- Pipelines, for building end-to-end ML workflows, based on containers
Until now, the Kubeflow community has presented applications on CPUs or GPUs. FPGAs can be used to speedup ML applications but so far the integration and the deployment was hard.
InAccel FPGA resource manager makes much easier the deployment and integration of FPGAs to higher programming frameworks. With InAccel FPGA plugin for Kubernetes, the applications can be easily accelerated without worrying about resource management and utilization of the FPGA cluster.
A complete guide on how to set up a complete machine learning application using FPGAs with Kubeflow on any existing Kubernetes cluster, is provided on this Tutorial lab.
The headache of every ML Engineer
Hyperparameter tuning is the process of optimizing the algorithm parameters to maximize the predictive accuracy of a model. If you don’t use Katib or a similar system for hyperparameter tuning, you would need to run many training jobs yourself, manually adjusting the hyperparameters to find the optimal values.
Searching for the best parameters takes away important time from other stages of the Data Science lifecycle. So, tools that monitor and automate this repetitive training process do not suffice and need to be accelerated, in order to let the professionals concentrate a bit more on stages like business understanding, data mining etc.
Accelerated XGBoost on Katib
XGBoost is a powerful machine learning library that has recently been dominating applied machine learning since it makes it really easy to build any predictive model. But, improving the model is difficult due to the many available parameters and requires careful tuning to fully leverage its advantages over other algorithms.
InAccel released in the past the IP core for accelerated XGBoost on FPGAs. This IP core helped to demonstrate the advantages of the FPGAs in the domain of ML and offered to the data science community the chance to experiment, deploy and utilize FPGAs in order to speedup their ML workloads. With Python, Java and Scala APIs provided, the developers do not need to change their code at all or worry about configuring FPGA accelerators.
Concerning Katib now, there are three steps in order to run your own experiment.
- Package your training applicaion in a Docker container image and make that image available in a registry.
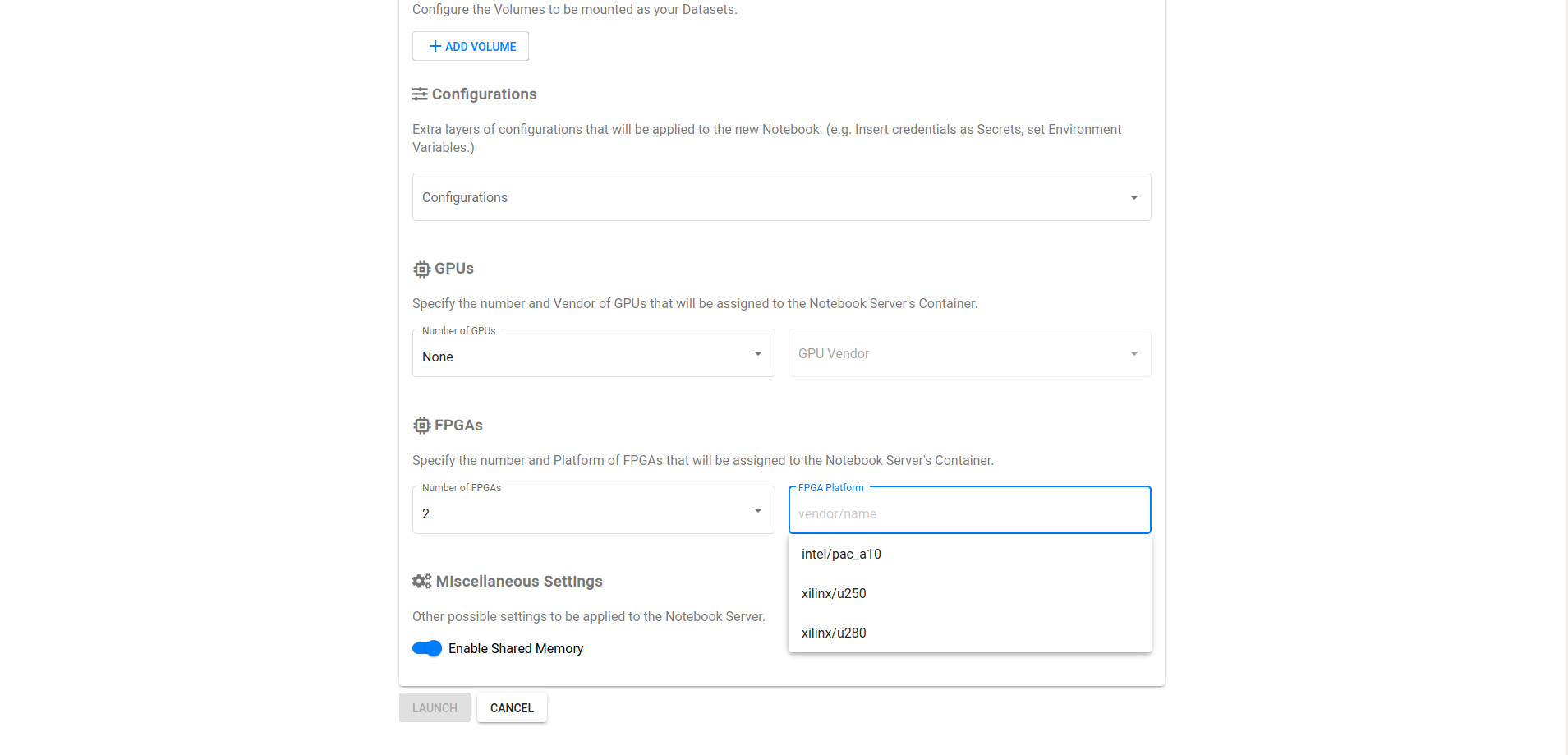
- Define the experiment specifications from Katib's 'Submit' UI or with a YAML configuration file, setting the parameters you want to tune, the objective metric, the number of trials and more. Finally, allocate the resources to enable the FPGA accelerated execution. E.g:
resources: limits: xilinx/aws-vu9p-f1: 1 - Run the experiment from the Katib UI by submiting the YAML file and monitor the trials.
Image classification on SVHN dataset
SVHN is a real-world image dataset, obtained from house numbers in Google Street View images. It consists of 99289 samples and 10 classes, with every sample being a 32-by-32 RGB image (3072 features).
The training code for the step 1 can be found on GitHub and is included inside inaccel/jupyter:scipy Docker image.
After defining the parameters, the search algorithm, the metrics and the other trial specifications we create a TrialTemplate YAML. In this file we:
- run the training application inside the container,
- define the algorithm's tree_method,
- get the accelerator's bitstream for XGBoost and
- allocate the resources as we mentioned previously.
For a CPU-only implementation we just need to change the tree_method to exact, hist etc.
Finally, we submit the experiment and navigate to the monitor screen.
- CPU-only training plot:
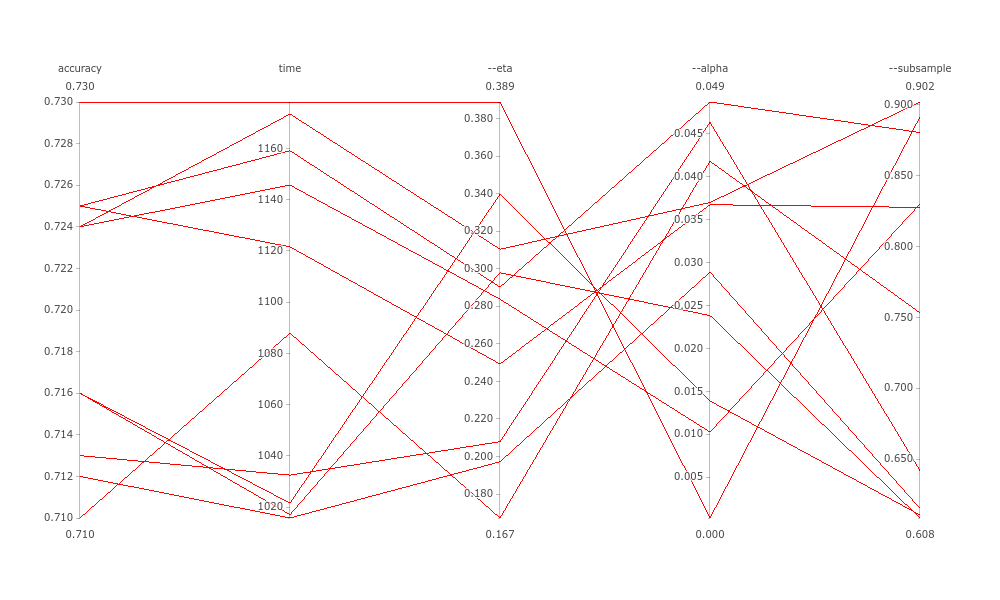
- FPGA-accelerated training plot:

In the above plots we see the objective metrics, accuracy and time, along with the three hyperparameters we chose to tune. We can keep the best combination of them, take more info or retry with another experiment. We notice that the accuracy is the same on both executions, but the CPU-only training takes 1100 seconds on average, while the FPGA-accelerated one lasts only 245 seconds. This means, that InAccel XGBoost achieves up to 4.5x speedup on this use case.
You will find a step-by-step tutorial here.
The following video also presents a complete walkthrough on how to submit a new experiment using Katib and highlights the extra steps needed for the FPGA deployment along with a small comparison of CPU and FPGA execution times.
https://www.youtube.com/watch?v=5_IMstcic6E
Authors:
Vangelis Gkiastas
Copyright: InAccel, Inc.