Customized compute acceleration in the datacenter is key to the wider roll-out of applications based on deep neural network (DNN) inference.
A great article by Xilinx Research Labs shows how to maximize the performance and scalability of FPGA-based pipeline dataflow DNN inference accelerators (DFAs) automatically on computing infrastructures consisting of multi-die, network-connected FPGAs. Xilinx as developed Elastic-DF, a novel resource partitioning tool which integrates with the DNN compiler FINN and utilizes 100Gbps Ethernet FPGA infrastructure, to achieve low-latency model-parallel inference without host involvement. Elastic-DF was applied to popular image classifiers ResNet50 and MobileNetV1 at XACC and provides significant throughput increase with no adverse impact on latency.
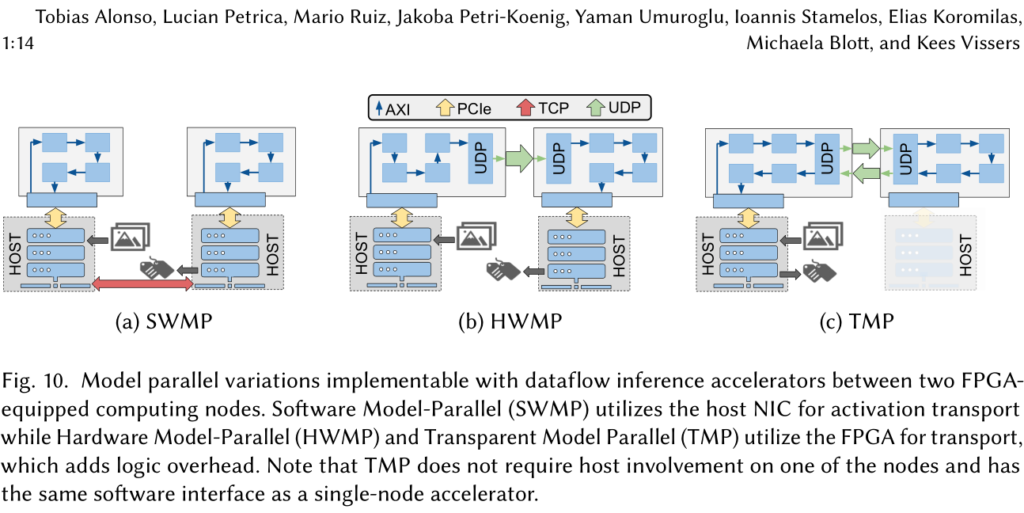
The paper, entitled “Elastic-DF : Scaling Performance of DNN Inference in FPGA Clouds through Automatic Partitioning” demonstrates that model-parallel multi-FPGA execution enables superlinear scaling of DFA performance in multi-FPGA systems, for both MobileNetV1 and ResNet-50. It also shows how constraints to Elastic-DF allows to implement software-transparent model parallelism (TMP) and also analyze how TMP compares with other forms of MP.
The MLPerf evaluation on multi-FPGA accelerators has been done using the InAccel Coral orchestrator and resource manager.
Coral is a fast and general-purpose accelerator orchestrator. It provides high-level APIs in C/C++, Java and Python which enable a user (the client) to make acceleration queries to a unified execution engine (the server) that supports every heterogeneous multi-accelerator platform. InAccel also
provides a runtime specification that vendors can use to advertise system hardware resources to Coral.
It aims to specify the configuration, and execution interface for the efficient management of any accelerator-based hardware resource (e.g. FPGAs), without customizing the code for Coral itself. In Coral, client applications call an accelerator on a local FPGA as if it were a software function, making it easier for the user to accelerate distributed applications and services. Coral users define a platform, i.e. the accelerators that can be called remotely with their arguments and configuration parameters. Coral clients and servers can run and communicate with each other in a variety of environments — from bare-metal Linux servers to containers inside a Kubernetes cluster — and applications can be written in any of Coral API’s supported languages.
The key concepts of the InAccel runtime specification are the following: resource, memory, buffer and compute unit. InAccel offers a default OpenCL-based Xilinx FPGA runtime implementation, where each resource object represents a single FPGA device with a list of memories and compute
units respectively, entities that is dynamically updated upon reconfiguration of the FPGA. Lastly, buffer objects belong to a specific memory inside the resource context, which corresponds to a physical memory region on the FPGA board’s DDR memories.
Dual-FPGA abstraction for Coral: To support multi-FPGA accelerators, we developed a custom InAccel runtime, enabling initialization-time configuration of the VNx and run-time synchronization between accelerator segments where applicable (HwMP, SwMP). In this new abstraction the resource object hosts the context of two devices (e.g. 2 Alveo U280), instead of one, but also a unified memory topology is announced to Coral. Each bitstream artifact is now a tarball that includes two named binaries, while the kernel metadata contain directives that indicate in which binary they reside.
By abstracting away all the lower level details, our Dual-FPGA Coral runtime is able to transform any dual-FPGA cluster to a single pool of accelerators. This enables us to run existing InAccel MLPerf test harnesses against our dual-FPGA accelerators with no changes to application code.
This runtime can be extended in principle to any number of FPGAs.
You can find the paper in this link.