Training a ML model can take a lot of time especially when you have to process huge amounts of data. Typical general-purpose processors (CPUs) or GPUs are designed to be flexible but are not very efficient on machine learning training. In the domain on embedded systems, that problem was solved many years ago by using specialized chips that are designed for specific applications (i.e. FPGAs). FPGAs are programmable chips that can be configured with specialized architectures. In the FPGAs, instructions that needs to process the data are hard-wired in the chip. Therefore, they can achieve much better performance than CPUs and consume much lower power.
At InAccel we have developed a Machine Learning suite for the FPGAs provided recently by aws that can be used without changing a single line of your code. The provided libraries overload the specific functions for the machine learning (e.g. logistic regression, k-means clustering, etc.) and the processor just offload the specific functions to the FPGA. FPGA can execute up to 12x faster the ML task and then return the data to the processor.
InAccel Accelerated ML suite supports C/C++, Java, Python and Scala and is also fully compatible with Apache Spark. That means that you can run your Spark ML applications on aws without changing your code and you get a 15x overall improvement instantly. The best thing is that at the same time you can also reduce the TCO. As the spark application will run 15x faster and the overall cost is the same as a typical r5.12x instance, you cat get up to 2x savings on your monthly bills.
MNIST Use case: Performance or Cost optimized
Performance optimized
The following example shows how you can speedup your applications and reduce the TCO for the MNIST dataset using logistic regression or K-means clustering.
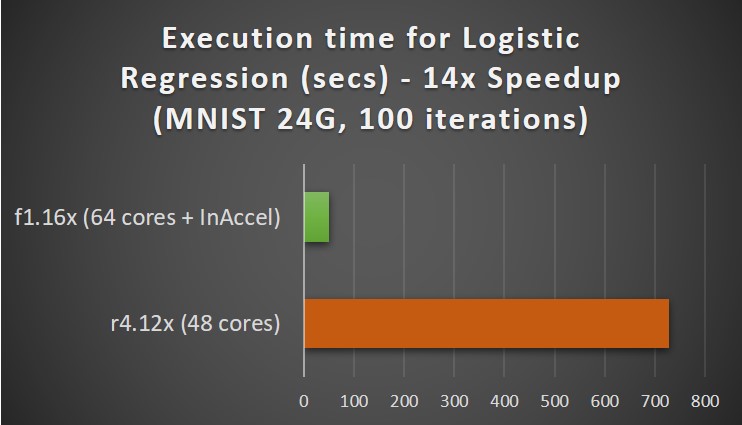
Running logistic regression for MNIST (24GB dataset, 100 iterations) on an r4.12x processor (48 cores) on AWS costs $3/hour and it takes around 728 seconds. That means that the total TCO is around $0.6 per training (total cost for running the application).
If you perform the training using InAccel's ML suite on AWS using the performance optimized f1.12x instances, the total execution time for the training drops to 51 seconds. The cost for f1.12x is $13.2/hour and the cost for InAccel IP core is $10/hour. That means $23.2/hour. However, as the total execution time is only 51 seconds instead of 728 seconds you get a 14x speedup (14 faster to get the results) and the TCO drops to $0.32 per training.
Cost optimized
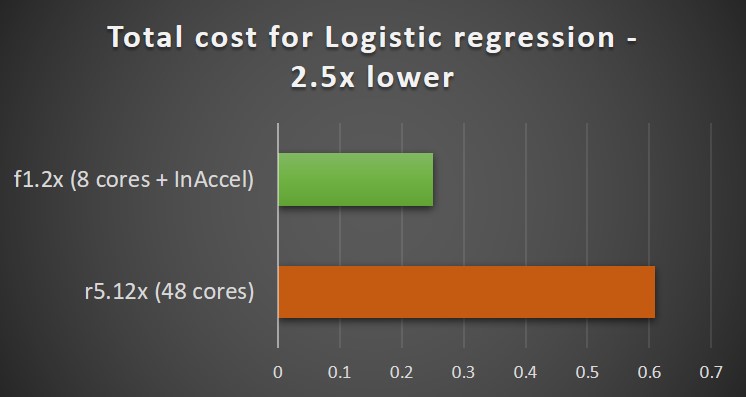
If the main goal is to reduce the TCO and the speedup is not so important for your applications, then you can select to use a low-cost instance (e.g. f1.2x) and get almost the same total execution time compared to r4.12x but the cost will drop to $0.25 per training.
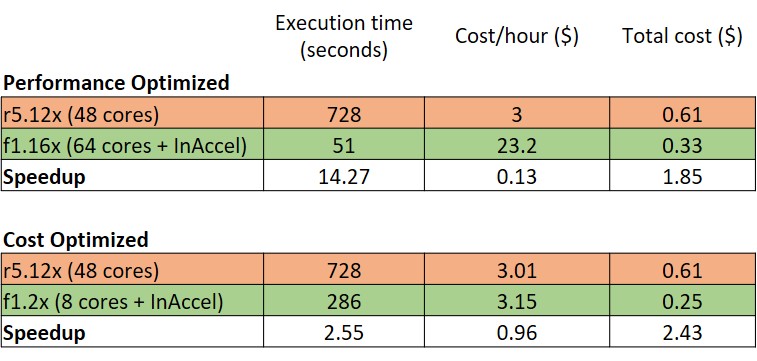
Logistic regression on AWS using InAccel FPGAs