Microsoft recently announced the availability of the new SQL Server 2019. SQL Server 2019 includes Apache Spark and Hadoop Distributed File System (HDFS) for scalable compute and storage. This new architecture that combines together the SQL Server database engine, Spark, and HDFS into a unified data platform is called a “big data cluster.”
SQL Server 2019 big data clusters allow users to deploy scalable clusters of SQL Server, Spark, and HDFS on top of Kubernetes. These components are running side by side and data can be prepared by using either Spark jobs or Transact-SQL (T-SQL) queries and fed into Machine Learning model training routines in either Spark or the SQL Server master. The obtained models can then be operationalized in batch scoring jobs in Spark, in T-SQL stored procedures for real-time scoring, or encapsulated in REST API containers hosted in the big data cluster. For more information regarding MSSQL Big Data Clusters check here.
At InAccel, we have developed a Machine Learning (ML) suite that seamlessly accelerates your Spark ML pipelines using FPGAs. The provided libraries overload the specific functions for the machine learning (e.g. logistic regression, k-means clustering, etc.) and the processor just offloads the specific functions to the FPGA. FPGA can execute up to 15x faster the respective ML tasks and then return the data to the processor.
To efficiently exploit the available FPGA resources as well as address the current limitations that FPGA-as-a-service is facing, we have also developed an FPGA Resource Manager named Coral. Coral acts as a node manager for the FPGA resources, receives acceleration requests from the applications, and is responsible for scheduling their execution in the available FPGAs, programming the FPGAs as well as transferring data from/to the application to/from the accelerator. Coral is able to handle multiple acceleration requests from both multiple applications as well as multiple threads of the same application. Coral is compatible with Kubernetes and Yarn and can be seamlessly integrated in your big data framework to accelerate your applications.
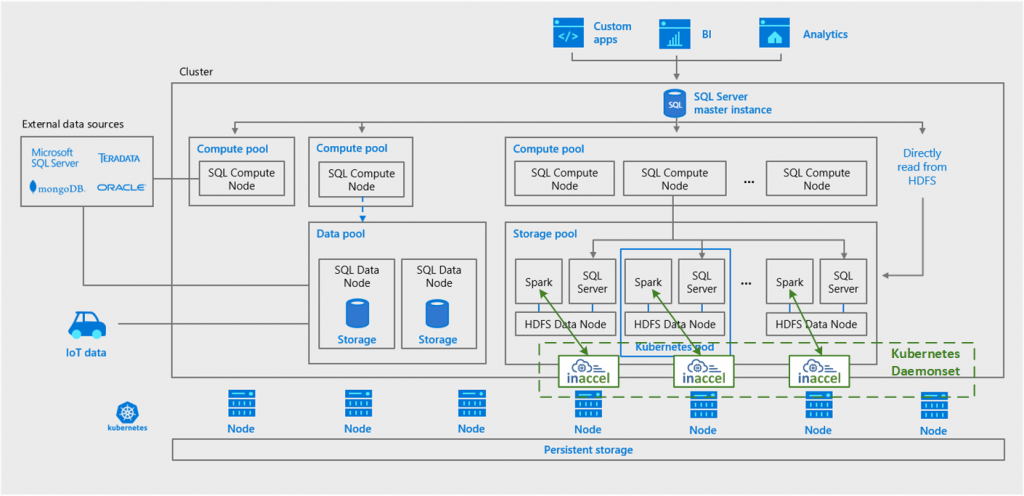
Accelerated Spark ML on top of Microsoft SQL Server 2019
Therefore, accelerating the ML-pipelines of your Microsoft SQL Server 2019 Big Data Clusters is as simple as running the following 4 commands
Step 1: Deploy Inaccel’s Coral FPGA manager as a Kubernetes DaemonSet
kubectl create -f coral-daemonset.yaml
After the deployment is finished, every FPGA accelerated node will run a Coral instance that serves as the node’s FPGA manager. Coral pod maps a port (default: 55677) to the node so that it can receive acceleration requests from the containers running on that node.
Step 2: Patch the Storage pool of the MSSQL Big Data cluster to enable it to interact with Coral
kubectl -n mssqlclustername mssql-storage-pool-default --patch “$(cat patch.yaml)”
This command patches the mssql-storage-pool-default StatefulSet so that i) it can have common shared memory with Coral in order to transfer inputs/outputs to/from the FPGA, and ii) it can discover Coral (sets the required environmental variable CORAL_HOSTNAME).
Step 3: Put the InAccel jars in the HDFS (as an alternative you may add them in the same location at every hadoop container).
This can be done by using Azure Data Studio, kubectl or curl. For example:
kubectl -n mssqlclustername cp ./inaccel mssql-storage-pool-default-0:/inaccel -c hadoop && kubectl -n mssqlclustername exec -ti mssql-storage-pool-default-0 -c hadoop -- hdfs dfs -put /inaccel /inaccel
Step 4: Seamlessly accelerate your Spark ML pipelines just by adding InAccel jars in your class path.
This can be done by either adding them in the Spark conf or by setting the respective arguments in the spark-submit command. For example:
spark-submit --master yarn --deploy-mode=cluster --conf spark.driver.extraClassPath=coral-api-1.1.jar:inaccel-spark-2.4.1.jar --conf spark.driver.extraClassPath=coral-api-1.1.jar:inaccel-spark-2.4.1.jar --jars hdfs:///inaccel/coral-api-1.1.jar,hdfs:///inaccel/inaccel-spark-2.4.1.jar,myApplication.jar myApplication.jar
Concluding, at InAccel we aim at seamless acceleration. As described above, you can accelerate your Microsoft SQL Server Big Data Cluster by only i) deploying Coral DaemonSet, ii) patching your Storage pool, and iii) putting Inaccel jars in your HDFS. You only need to do this once! Next, each time you run a Spark ML pipeline, you can benefit from up to 15x speedup without changing a single line of your code.
1 comment
Tyree April 29, 2019
I enjoy the report