Red Hat OpenShift is an open source container application platform based on the Kubernetes container orchestrator for enterprise application development and deployment.
OpenShift empowers developers to innovate and ship faster with the leading hybrid cloud, enterprise container platform. It offers automated installation, upgrades, and lifecycle management throughout the container stack — the operating system, Kubernetes and cluster services, and applications — on any cloud.
The Openshift UI has several useful functionalities, allowing one to monitor the container resources, container health, the nodes the containers reside on, IP addresses of the nodes, etc.
OpenShift allows easy deployment of any application, like a Jupyter Notebook. Jupyter Notebooks are widely used in Machine Learning applications, and allow instant development and deployment of ML code in an easy-to-use framework. However, many notebook applications need to process huge amounts of data and in cases like ML training the total execution time is critical for many users.
Hardware accelerators, like FPGAs, can be used to speedup ML applications by more than 10x but usually they lack frameworks for zero-configuration deployment. Also, the lack of a user-friendly API makes the integration quite challenging.
InAccel, a pioneer on the domain of application acceleration, has released today the easiest way to utilize FPGA-based accelerators over OpenShift Container Platform. InAccel has developed a unique FPGA accelerator orchestrator that abstracts away the FPGA resources making much easier the deployment, scaling and automated resource management of the accelerators on any FPGA cluster. Using a powerful tool like OpenShift, users can now deploy their applications on the cloud utilizing the power of FPGAs, easier than ever.
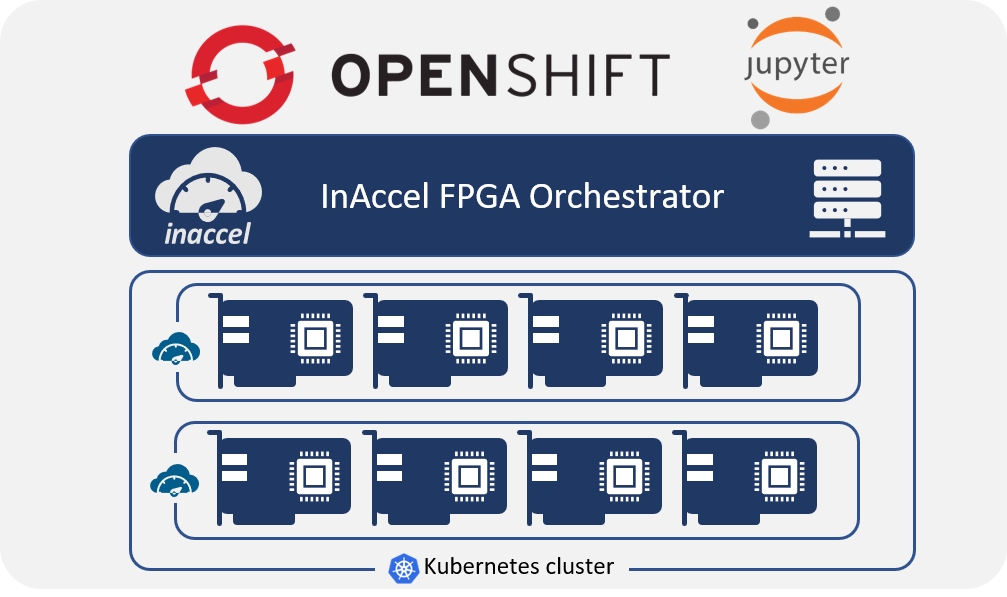
InAccel Coral FPGA accelerator orchestrator is a framework that allows the distributed acceleration of large data sets across clusters of FPGA resources using simple programming models. It is designed to scale up from single devices to hundreds of FPGAs, each offering local computation and storage.
A complete guide on how to set up and deploy FPGA-enabled applications atop OpenShift on AWS, is provided in this Tutorial lab.
You can also check the following video for a complete walkthrough on how to deploy a new FPGA-accelerated Jupyter application:
https://www.youtube.com/watch?v=zaLRIXKkeYc