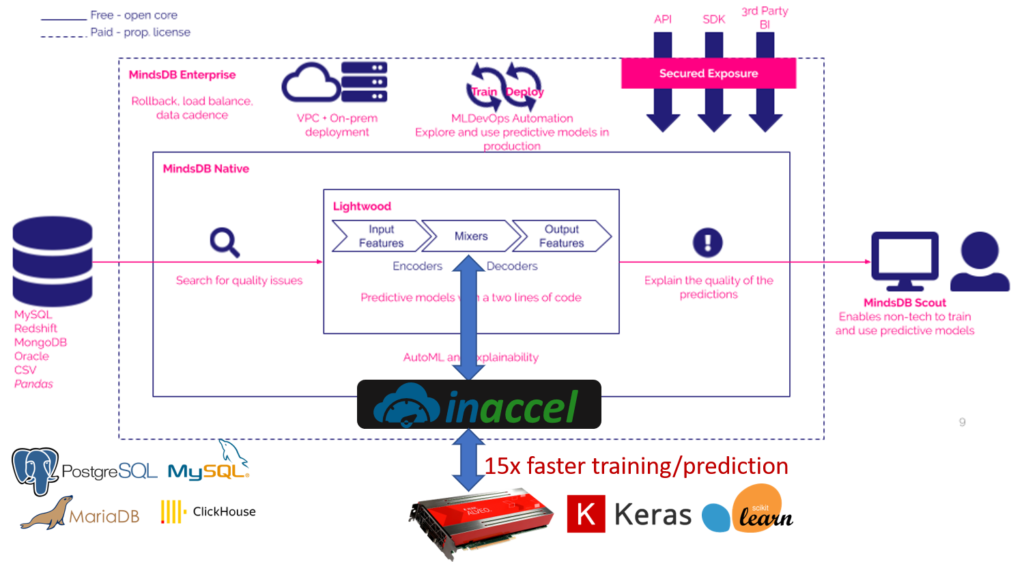
MindsDB is an open-source AI layer for existing databases that allows you to effortlessly develop, train and deploy state-of-the-art machine learning models using SQL queries. For more flexibility MindsDB has developed the Lightwood framework. Lightwood has one main class, the Predictor, which is a modular construct that you can train and get predictions from. It is made out of 3 main building blocks (features, encoders, mixers) that you can configure, modify and expand as you wish.
However, in many cases the training or the prediction task for machine learning can be quite computational intensive. This means that the training or the prediction can sometimes last for several minutes or hours especially when we have to process huge amounts of data. In that case specialized hardware accelerators (i.e. FPGAs) can be used to speed up the training and the prediction. However, in many cases the utilization and the deployment of the FPGAs is not straightforward and required significant experience on the domain of FPGAs.
InAccel, a world-pioneer on the domain of FPGA deployment, allows easy integration of FPGA on widely used frameworks like Spark, Scikit-learn, Keras, Jupyter notebooks and now MindsDB. InAccel provides a unique FPGA resource manager that allows seamless integration of the FPGAs with high-level programming languages and data science frameworks. The Coral FPGA manager allows easy deployment, scaling and resource management of the FPGA resources. It comes with an API that allows computational intensive functions to be offloaded to the FPGAs as easy as any function invoking in software libraries. Also it provides several FPGA-based IP cores for the acceleration of typical machine learning algorithms like logistic regression, k-means clustering, naive bayes and XGBoost.
InAccel provides the Logistic Regression accelerator which can accelerate the training time of a machine learning model and it is available for Intel’s Arria10 FPGAs, Amazon EC2 F1 instances and Xilinx’s Alveo U200, U250 and U280 FPGA platforms. So we developed a LogisticRegression class that can be selected as the desired mixer to create the Lightwood Predictor.
In this case, the most time consuming part which is the training of the model is executed on one of the available FPGAs using InAccel’s Logistic Regression accelerator. The major benefit of this integration is that the user can easily load data from his database using the MindsDB data sources. The database can be MARIADB, MYSQL, POSTGRESQL, CLICKHOUSE, SQL SERVER or SNOWFLAKE and the selection of the data to be trained on the FPGA can be done with a simple command. That way users can experience up to 15x faster training without any code changes.
The following picture shows how InAccel framework has been integrated to MindsDB to allow acceleration to ML tasks using the FPGAs available on-prem or on the cloud.
You can run a simple example on InAccel Studio
Import the required libraries
import pandas as pd from lightwood import Predictor from inaccel_sklearn_mixer import LogisticRegression
Load historical data
df = pd.read_csv('https://mindsdb-example-data.s3.eu-west-2.amazonaws.com/home_rentals.csv')
Train a new predictor using FPGAs
predictor = Predictor(config) predictor.learn(from_data=df)
Make predictions
df = df.drop([x['name'] for x in config['output_features']], axis=1) results = predictor.predict(when_data=df)