Machine learning applications require powerful and scalable computing systems that can sustain the high computation complexity of these applications. Companies that are working on the domain of machine learning have to allocate a significant amount of their budget for the OpEx of machine learning applications whether this is done on cloud or on-prem.
Typical machine learning application can scale to as much as 100 nodes or higher (servers) to provide useful results, increasing significantly the TCO. However, cloud providers (like AWS, Alibaba and Nimbix) have started deploying new platforms that can be used to speedup and reduce the OpEx of these applications. Programmable hardware accelerators, like FPGAs, can provide much higher throughput compared to CPUs and GPUs and at the same time help reduce the OpEx of computational intensive applications.
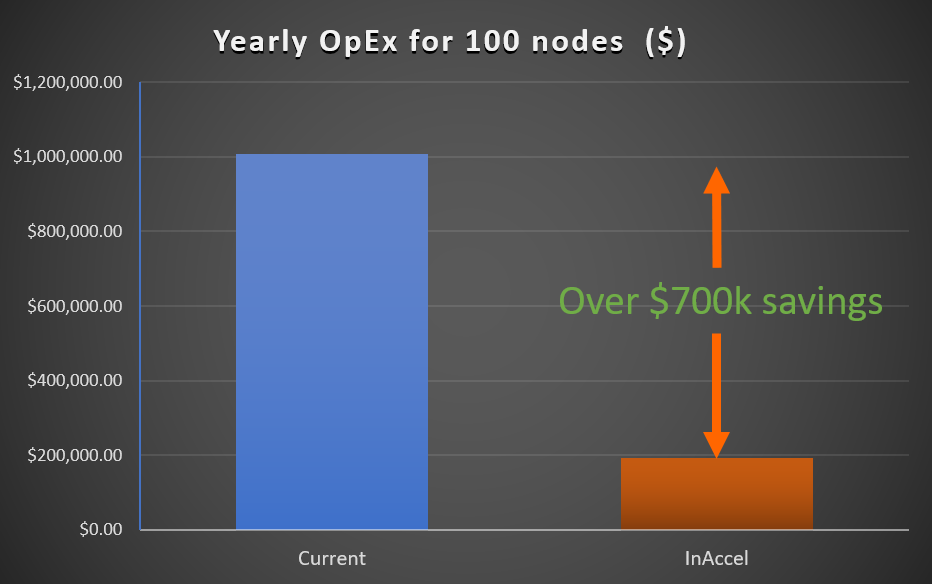
In this use case we show an example on how a company can save over $700K by utilizing hardware accelerators in the cloud or on-prem.
Use case: Training on logistic regression on 100 nodes
One of the most widely used applications in the domain of machine learning is logistic regression. Logistic Regression is used for building predictive models for many complex pattern-matching and classification problems. It is used widely in such diverse areas as bioinformatics, finance and data analytics. In this case, we evaluate the total OpEx for training a large dataset on 100 nodes. We evaluate the performance and the cost on the large MNIST dataset (however any other dataset can be applied).
If a company is using a cluster of 100 nodes for the machine learning training, the total cost on a yearly basis is around $1,007,400 (assuming a cluster of r5d.4x on aws that costs $1.15/hour and assuming 24/7 operation.)
R5d.4x cost: $1.15*24*365*100 = $1,007,400
However, if the same company utilize the new f1 instances on AWS, it can speedup significantly the training of the models and at the same time to reduce significantly the OpEX. The accelerated ML suite from InAccel that is tailored made for the f1 instances on aws can achieve up to 15x speedup compared to r5d.4x for the training of logistic regression. That means that the company can either select to run their applications 15x faster using the same number of nodes or it can reduce the number of nodes by 15x. The figure below shows that total OpEx savings using the hardware accelerators (f1) on aws.
f1.4x cost: $3.3*24*365*6.66 = $192,527
To use the hardware accelerators, in the past you had to change your application in order to make sure that the processor will offload the most computational intensive algorithms in the hardware accelerators. However, using InAccel's libraries, the user does not have to change a single line of code. ML applications, e.g. based on Apache Spark, can run seamlessly without changing their code at all and just by pulling InAccel's docker-based FPGA resource manager. Even taking into account the license fees for the FPGA resource manager (80k/year for 100-node cluster) the company can save over $700k in total.
Examples on how to test and deploy your machine learning applications using accelerators instantly are available both on AWS and on Nimbix.
InAccel machine learning savings OpEX