Inspur has recently announced the open-source release of TF2, an FPGA-based efficient AI computing framework. The inference engine of this framework employs the world’s first DNN shift computing technology, combined with a number of the latest optimization techniques, to achieve FPGA-based high-performance low-latency deployment of universal deep learning models. TF2 is an open-sourced FPGA-based AI framework that contains comprehensive solutions ranging from model pruning, compression, quantization, and a general DNN inference computing architecture based on FPGA.
The open source project can be found at https://github.com/TF2-Engine/TF2.
TF2 consists of two parts. The first part is the model optimization and conversion tool TF2 Transform Kit, which can conduct compression, pruning, and 8-bit quantization of network model data trained by frameworks such as PyTorch, TensorFlow and Caffe, thereby reducing the amount of model calculations.
The second part is the FPGA intelligent running engine TF2 Runtime Engine, which can automatically convert optimized model files into FPGA target running files, and greatly improve the performance and effectively reduce the actual operating power consumption of FPGA inference calculations through the innovative DNN shift computing technology. Testing and verification of TF2 have been completed on mainstream DNN models such as ResNet50, FaceNet, GoogLeNet, and SqueezeNet.
In this case we show how InAccel orchestrator can be integrated with TF2 to allow multi-tenant scalable deployment of TF2 to a cluster of Intel-based FPGAs.
We show how InAccel’s orchestrator allows easy deployment, scaling, resource management, and task scheduling for FPGAs making it easier than ever, the deployment and the utilization of FPGA for Deep Learning Inference.

InAccel PAC cluster manager
In cases that multiple applications or processes need to utilize the PAC-based accelerators, and the application needs to be deployed in multiple servers, InAccel® Coral manager is used to abstract away the available resources and provide a simple API for software developers. InAccel Coral orchestrator abstracts away the available resources in a cluster of PAC cards, making it easier than ever to deploy one or more applications targeting multiple FPGAs.
InAccel’s manager is used to schedule, dispatch and manage the functions that need to be accelerated. It performs the load balancing among the available resources in the PAC cluster and is also used for the management and configuration of the cards based on the functions that are offloaded.
Software developers can simply call the functions that need to be accelerated without worrying on the scheduling of the functions to the available resources or the contention of the resources from multiple applications.
InAccel’s orchestrator is fully compatible with Inspur Deep Learning Inference Accelerator and the Intel® PAC cards.
InAccel Orchestration and Integration
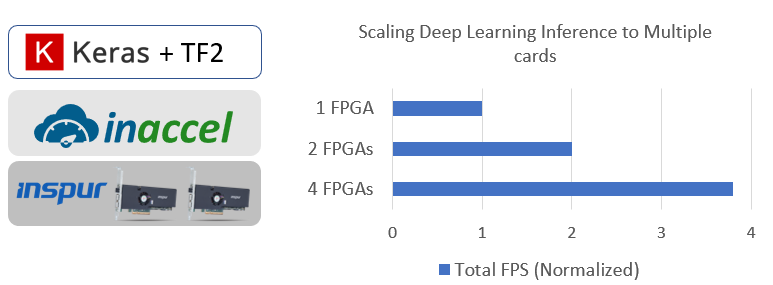
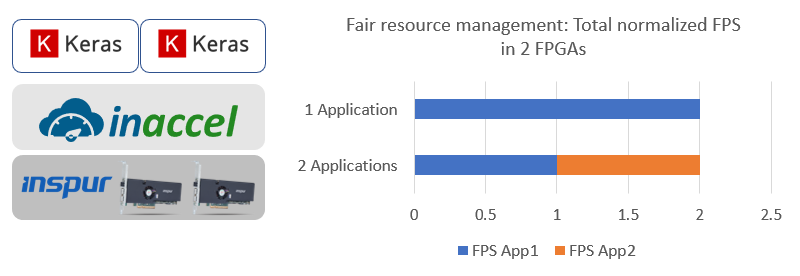
Using InAccel orchestrator, Inspur TF2 Deep Learning Inference Accelerator can be deployed on a cluster of FPGAs instantly. It also allows sharing of the available resource to multiple users or multiple applications.
InAccel orchestrator performs automatically the dispatching of the workload to the available resources performing the load balancing, the resource management and the serialization of the requests.
The main advantage of the InAccel orchestrator is that it can be integrated easily and does not add any overhead on the Inspur accelerators.
The following figure shows the scaling of the accelerator to multiple FPGAs and the sharing of the resources to multiple users.