FPGA are programmable platforms that can be configured with customized architectures optimized for specific applications. These tailored-made architectures can execute specific applications much faster compared to typical general-purpose processors. In the last years, FPGAs have been evolved from simple programmable logic gates to powerful heterogeneous platforms with specialized modules for machine learning, DSP, networking, and data processing.
At the same time, FPGA vendors have developed new EDA tools that allow the design of specialized architectures from higher level programming languages like OpenCL and C/C++ (High-level Synthesis).
The main advantage of the FPGAs is that they can offer much higher performance compared to general purpose processors, and in some case better energy efficiency compared to GPUs. FPGAs in some cases can offer as much as 100x speedup (two orders of magnitude) compared to typical processors. At the same time the flexibility that they offer make it much more attractive compared to ASIC in cases that time-to-market is critical and the cost of ASIC continue to increase significantly.
However, until now the main barrier for the widespread adoption of the FPGA in application like HPC, big data analytics, machine learning, genomics and financial applications was the high programming complexity of the FPGA deployment.
Using the frameworks provided by the FPGA vendors, users need to invoke the functions calls that they want to accelerate through OpenCL and they need to learn what is a bitstream (configuration file for programming the FPGA), and how to handle the buffer management for the communication to the FPGA. These issues add significant overhead to the software or the data and machine learning engineers.
In order to allow the widespread adoption of the FPGAs, software users need to be able to deploy and accelerate their application as easy as it is currently done using CPUs and GPUs. The users do not need to know about bitstream or buffer allocation. Users need to be able to invoke the functions that they want to accelerate from multiple threads, multiple processes or multiple applications. Users need to be able to scale their application in a cluster of FPGAs as easy as it is done using Kubernetes or spark .
InAccel’s mission is to offer to the software community the advantages of the hardware accelerators (high throughput, low latency and high energy efficiency) without any additional effort. InAccel’s mission is to provide the required framework that allow the seamless utilization of FPGAs offering significant speedups in applications like machine learning, data analytics, genomics, financial and HPC applications.
InAccel’s Coral FPGA cluster manager was developed having in mind the software user that want to speedup their applications without changing the code at all and without having to know anything about FPGAs.
First of all, InAccel decouples the host code completely from the hardware kernel. A separate repository is used where the FPGA developers can upload all the functions that have been accelerated in the form of IP blocks. Software users do not need to change their code at all and can invoke the functions that can be accelerated using typical programming languages like C/C++, Python and Java. Software users do no need to add to their code the name of the bitstreams or the buffer management that will be used for the communication with the FPGA. InAccel framework automatically overload the specific functions to be offloaded to the FPGA resources.
Furthermore, InAccel abstracts away the FPGA resources making feasible the utilization of the FPGA resources from multiple threads, processes or applications. That way, users can utilize the efficiency of the FPGAs without worrying about conflicts and access to the FPGA resources. In the same way, the software code is serialized in the CPUs, InAccel manager serializes the requests for specific tasks to be accelerated based on the available FPGA resources.
Finally, InAccel allows the instant scaling of applications to multiple FPGAs. Software programmers can invoke as many time they want the function to be accelerated from the same thread or different thread or even different applications. Each function invoking is translated to a request for acceleration to the FPGA manager and the manager performs the load balancing and the dispatching of the requests to the available FPGAs in the cluster (multiple FPGAs in the same server). If a user wants to scale it to multiple servers, this is possible using the Kubernetes plugin of Inaccel’s FPGA manager.
Therefore, InAccel FPGA manager offers a unique, novel and integrated solution that allow software programmers to speedup their applications, increase the energy efficiency and reduce the TCO without any overhead and without adding any complexity to their applications. That way, they can enjoy all the benefits of the hardware accelerators without knowing anything about the FPGAs.
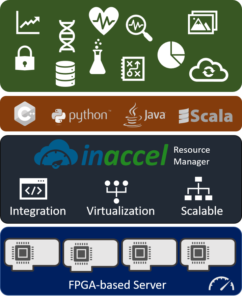
InAccel FPGA resource manager