Deep neural networks, and AI in general, can offer tremendous advantages in many sectors like healthcare, finance, logistics, marketing, and research. However, all the AI models like deep learning, reinforcement learning, etc. are computationally intensive and require enormously powerful processing platforms. This is the reason that so many large chip vendors and startups have been focused on the development of powerful specialized processing systems specifically for AI algorithms.
Karl Freund, liken the explosion of several AI chip vendors to the Cambrian period with the rapid diversification of life forms, known as the Cambrian explosion. There are several vendors providing specialized chips other using typical silicon processes and others using emerging technologies like quantum computing and neurocomputing. Shan Tang has published the AI chip landscape that shows all the major players on the domain of deep learning accelerators and now it hosts more than 50 companies (both startup and large established enterprises including cerebras, graphcore, groq, and sambanova to name a few).
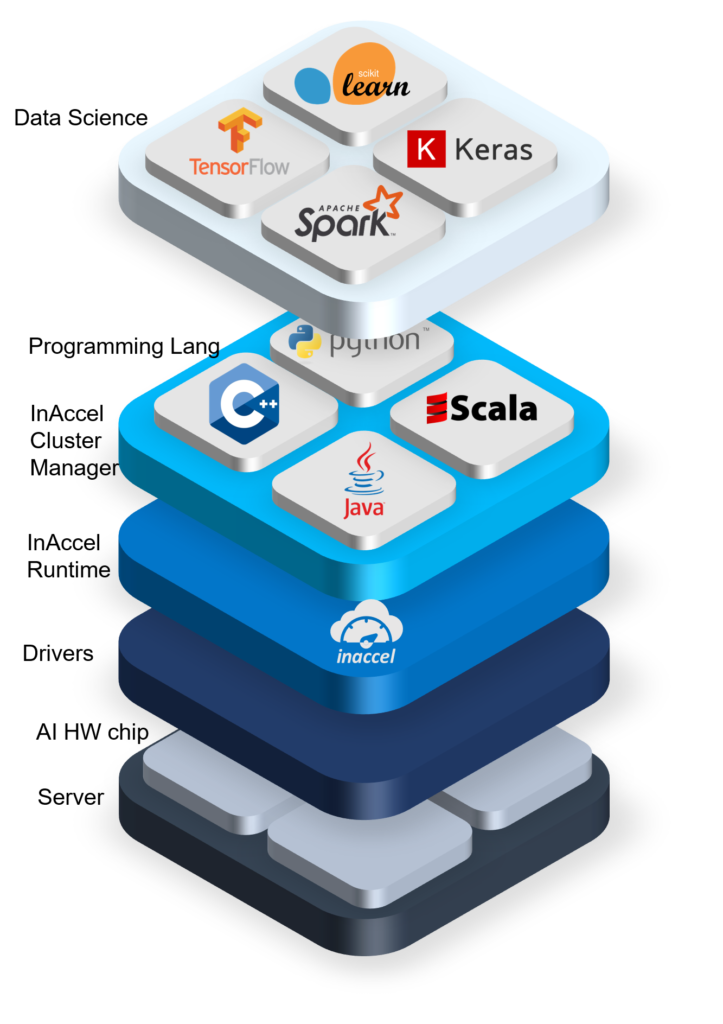
However, as we have witnessed in the past, one of the critical factors for the adoption and success of a hardware platform is the availability of the required software stack. An efficient software stack, that will allow the easy integration and seamless utilization of the hardware resources from the programming languages and the data science frameworks (Pytorch, Keras, Tensorflow). In the past we have seen several computing architectures with great performance to fail from widespread adoption due to limited support and availability of the software stack that will allow easy integration with typical programming framework. For example, dataflow architectures (used for example on network processing) could provide high performance but it was hard to be integrated with widely used programming frameworks.
Google for example, has identified this challenge and managed to develop the Tensorflow Processing Unit (TPU) with fully support of Tensorflow as the main programming framework. Actually, it was so successful on this that users do not even have to change the code at all when their applications are running on TPUs.
Therefore a critical issue on the adoption of the AI chip from the data scientists and data engineers will be the easy of integration with the data science and data engineering platforms. Data scientists care on how their applications developed in Kera, Pytorch or tensorflow can run on these AI chips with the minimum number of changes (ideally zero changes). Sometimes, the speedup that the accelerators provide must be more than 10x in order the users to bother changing their code at all (even if it means using a very simple API).
Data engineers on the other hand they care about the easy of deployment, easy scaling and sharing of resources from multiple users. There is no point of porting your application in an accelerator if your application cannot be scaled efficiently on multiple nodes in the same way that is done on the CPU world. They also care about efficient resource management. CPUs supports virtualization that allows much more efficient resource management. Similarly, hardware AI accelerators must support efficient resource management that will allow multiple users to share the available resources in the most efficient way. Also, AI hardware vendors must provide the required libraries that will allow integration with cluster managers and efficient orchestration using Kubernetes, Mesos, Yarn, etc.
This is why at inaccel we have been focused on the development of a vendor-agnostic resource manager and orchestrator that allows:
- Seamless integration with programming languages and high-level frameworks
- Instant scaling on multiple nodes and
- Efficient resource management of the hardware resources from multiple threads/users
The latest version of the Coral resource manager allows the software community to instantiate and utilize a cluster of AI hardware accelerators with the same easy as invoking typical software functions. InAccel’s Coral resource manager allows multiple applications to share and utilize a cluster of accelerators in the same node (server) without worrying about the scheduling, load balancing and the resource management of each accelerator.
InAccel’s Coral FPGA resource manager is available as a docker container for easy installation. Also, it provides a light-weight graphical monitoring tool that allows users to get useful insight into the operation of the accelerators.
InAccel’s Coral resource manager covers an essential missing part in the AI HW chips ecosystem as it allows software programmers to access HW accelerators seamlessly and treat them in the same way as CPUs in terms of scaling and resource management.
InAccel’s Coral FPGA resource manager is available on two versions: a free community edition with limited features and the enterprise edition.