What is InAccel?
InAccel offers 1-click deployment of FPGA workloads on premises, on cloud, using Docker, Podman, Singularity or Kubernetes. By taking care of the whole FPGA acceleration lifecycle we make it possible for you to focus on the application. The limit is your imagination!

Easy Deployment
Automatic Scaling
Resource Orchestration
Resource Monitoring

Faster Execution

Cost Reduction
Trusted By

Products
InAccel started as an IP core production company and later on transformed to the company it is today to help the adoption of FPGAs. InAccel still develops IP cores for customers and has a pool of available IP cores mainly targeting the domain of Machine Learning.
InAccel offers an end-to-end Bitstream repository solution covering the deployment lifecycle of your FPGA binaries to manage target platforms, allow artifact versioning and accelerator distribution.

Coral is a framework that registers possible the distributed acceleration of large data sets across clusters of FPGA resources using simple programming models. It abstracts away the FPGA resources to a pool of accelerators and takes care of scheduling and orchestrating jobs for acceleration.
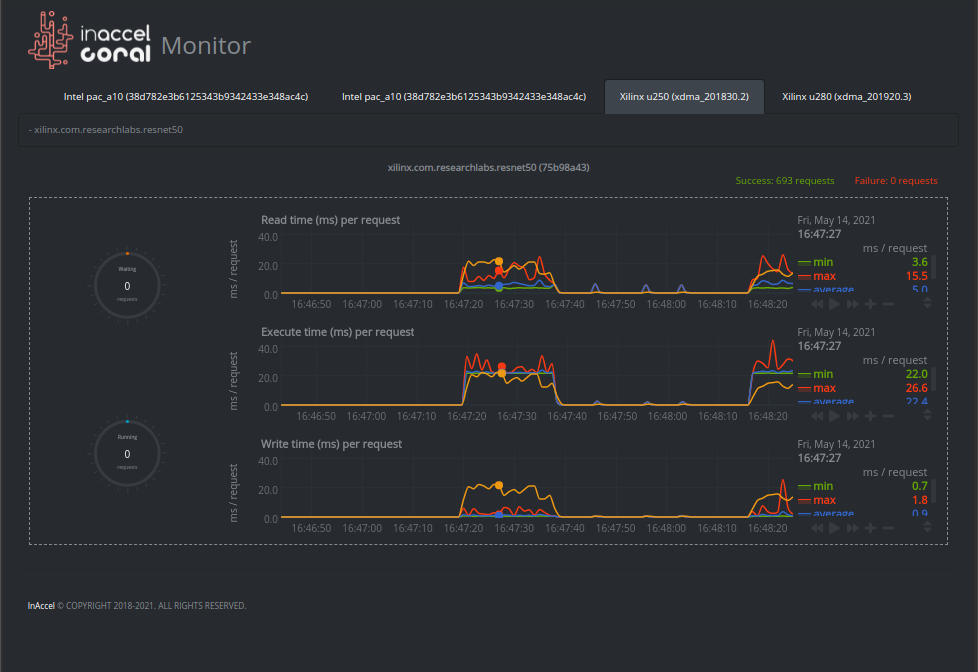
Coral monitor is a real-time monitoring tool designed specifically for custom resources like FPGAs and GPUs. It can provide power, thermal and structural information as well as details for all the running tasks.

Use Cases
InAccel provides all the tools required to get you started with hardware acceleration. It brings together version control of bitsteam artifacts, resource orchestration and monitoring so that users can benefit from the power of hardware accelerators whilst building scalable pipelines on environments that they are already familiar with, to provide production level real-life applications. For any computationally intensive application , our products can be used to reduce the execution time and reduce the energy footprint.
Below you can have a quick look on ready-to-use demos for a wide range of use cases:
Below you can have a quick look on ready-to-use demos for a wide range of use cases:
-
Machine Learning
Logistic Regression
Xilinx/Intel
trainKMeans
Xilinx/Intel
trainNaive Bayes
Xilinx/Intel
inferenceXGBoost
Xilinx
trainDeep Learning
ResNet50
Xilinx
inferenceMobileNet
Xilinx
inferenceGenomics
BWA Mem
Intel
PairHMM
Intel
Smith Waterman
Intel/Xilinx
Financial
Black Scholes
Intel/Xilinx
Binomial
Xilinx
PDE
Intel
Monte Carlo
Intel/Xilinx
Computer Vision
Color Detect
Xilinx
Stereo BM
Xilinx
Compression
Lz4
Xilinx
compressGZip
Xilinx
compressEncryption/Decryption
AES
Intel/Xilinx
128 CBC
128 CTR
128 ECBSolutions
Thanks to the products that we have made available - that take care of the whole acceleration life-cycle - it is easier than ever to enable hardware acceleration in any project/framework. To showcase the simplicity and easiness of integrating InAccel with state of the art frameworks, we offer all the solutions you can find below and many more in the Samples section of our Documentation.-

Jupyterhub for FPGAs
-

Using OpenShift for accelerated Data Analytics
-

Deep Learning for humans
-

FPGA Accelerated Machine Learning in Python
-

FPGA Accelerated Spark ML
-

Accelerate ML workflows on Kubeflow
-

Zero to FPGAs using BinderHub
-

Accelerated Spark ML on top Microsoft SQL Server 2019 Big Data Cluster
-

High-performance TensorFlow library for quantitative finance
-

Multi-tenant, enterprise-grade FPGA cluster deployment using Kubesphere console
Simple, transparent pricing
FreeCommunity
APIs in C++, Java, Python and RustUnlimited nodesOne (1) FPGA per nodeNative CLI automation toolBitstream packaging and versioning---300$/node/monthEnterprise
APIs in C++, Java, Python and RustUnlimited nodesUnlimited FPGAs per nodeNative CLI automation toolBitstream packaging and versioningInAccel Coral AddonsWeb UI to monitor your FPGA resourcesBitstream deployment pipelines24x7 uptime supportEnd User Community







Partners




Research

Testimonials
InAccel framework gives you a great abstraction layer resulting in less code. It has a monitoring tool and other language bindings like Python, etc. making it very easy to integrate with our applications.
...this is where InAccel's framework helps immensely: we don't need to code MT C++, rather we call the FPGA from multiple workers and we let the InAccel framework schedule the FPGA workloads as fast as possibleFred Tsang
We found it very useful as it allows high-level abstracted kernel calls instead of OpenCL which requires complex implementation of FPGA kernel calls.
Jongwoo Kim