Data scientists and ML engineers can now speedup their deep learning applications using the power of FPGA accelerators from their browser.
FPGAs are adaptable hardware platforms that can offer great performance, low-latency and reduced OpEx for applications like machine learning, video processing, quantitative finance, etc. However, the easy and efficient deployment from users with no prior knowledge on FPGA was challenging.
InAccel, a pioneer on application acceleration, makes accessible the power of FPGA acceleration from your browser. Data scientists and ML engineers can now easily deploy and manage FPGAs, speeding up compute-intense workloads and reduce total cost of ownership with zero code changes.
InAccel provides an FPGA resource manager that allows the instant deployment, scaling and resource management of FPGAs making easier than ever the utilization of FPGAs for applications like machine learning, data processing, data analytics and many more applications. Users can deploy their application from Python, Spark, Jupyter notebooks or even terminals.
Through the JupyterHub integration, users can now enjoy all the benefits that JupyterHub provide such as easy access to computational environment for instant execution of Jupyter notebooks. At the same time, users can now enjoy the benefits of FPGAs such as lower-latency, lower execution time and much higher performance without any prior-knowledge of FPGAs. InAccel’s framework allows the use of Xilinx’s Vitis Open-Source optimized libraries or 3rd party IP cores (for deep learning, machine learning, data analytics, genomics, compression, encryption and computer vision applications.)
The Accelerated Machine Learning Platform provided by InAccel’s FPGA orchestrator can be used either on-prem or on cloud. That way, users can enjoy the simplicity of the Jupyter notebooks and at the same time experience significant speedups on their applications.
Users can test for free the available libraries on the InAccel cluster on the following link: https://inaccel.com/accelerated-data-science/
Accelerated Inference — A use case on ResNet50
Any user can now enjoy the speedup of the FPGA accelerators from their browser. In the DL example we show how users can enjoy much faster ResNet50 inference from the same Keras python notebook with zero code changes.
Users can login on the InAccel portal using their Google account at https://studio.inaccel.com
They can found ready to use example for Keras on Resnet50.
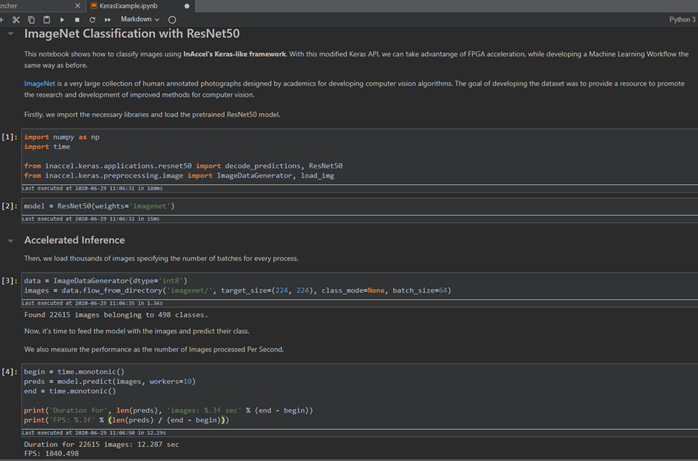
The user can see that the python code is exactly as the one that would be running on any CPU/processor. However in this example users can experience up to 2,000 FPS inference on ResNet50 with zero code changes.
The user can test the accelerated Keras ResNet50 inference example either with the available dataset (22,000 images) or they can download their own dataset.
They can also confirm that the results are correct using the validation code as it is shown below.
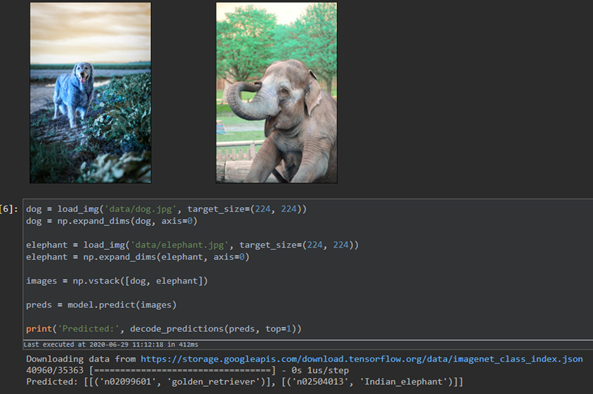
You can check the relevant video on Youtube:
https://www.youtube.com/watch?v=42bsjdXVmFg
Note: The platform is available for demonstration purposes. Multiple users may access the available cluster with the 2 Alveo cards and it may affect the performance of the platform. If you are interested to deploy your own data center with multiple FPGA cards or run your applications on the cloud exclusively, contact us at info@inaccel.com.
The accelerator for the ResNet50 inference is provided by Xilinx