Microsoft recently announced the availability of the new SQL Server 2019. SQL Server 2019 includes Apache Spark and Hadoop Distributed File System (HDFS) for scalable compute and storage. This new architecture that combines together the SQL Server database engine, Spark, and HDFS into a unified data platform is called a “big data cluster.”
SQL Server 2019 big data clusters allow users to deploy scalable clusters of SQL Server, Spark, and HDFS on top of Kubernetes. These components are running side by side and data can be prepared by using either Spark jobs or Transact-SQL (T-SQL) queries and fed into Machine Learning model training routines in either Spark or the SQL Server master. The obtained models can then be operationalized in batch scoring jobs in Spark, in T-SQL stored procedures for real-time scoring, or encapsulated in REST API containers hosted in the big data cluster. For more information regarding MSSQL Big Data Clusters check here.
At InAccel, we have developed a Machine Learning (ML) suite that seamlessly accelerates your Spark ML pipelines using FPGAs. The provided libraries overload the specific functions for the machine learning (e.g. logistic regression, k-means clustering, etc.) and the processor just offloads the specific functions to the FPGA. FPGA can execute up to 10x faster the respective ML tasks and then return the data to the processor.
To efficiently exploit the available FPGA resources as well as address the current limitations that FPGA-as-a-service is facing, we have also developed an FPGA Resource Manager named Coral. InAccel Coral acts as a cluster manager (orchestrator) for the FPGA resources, receives acceleration requests from the applications, and is responsible for scheduling their execution in the available FPGAs, programming the FPGAs as well as transferring data from/to the application to/from the accelerator. Coral is able to handle multiple acceleration requests from both multiple applications as well as multiple threads of the same application. Coral FPGA cluster manager is compatible with Kubernetes and Yarn and can be seamlessly integrated in your big data framework to accelerate your applications.
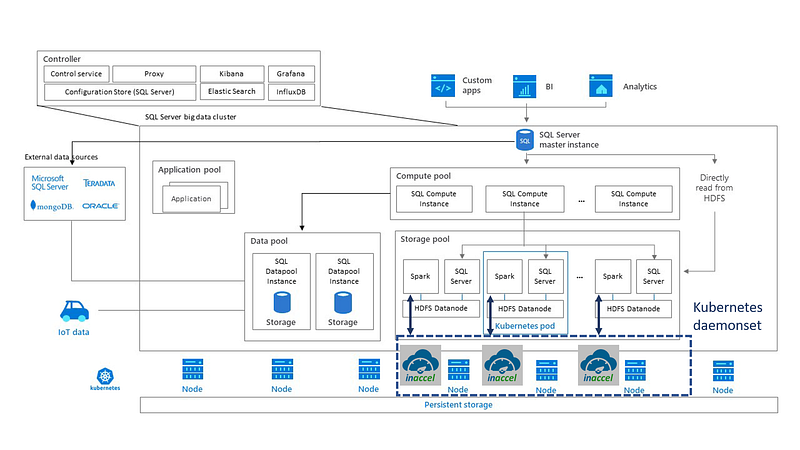
In a case of an application with streaming data from Kafka or Spark streaming that use SQL Server to store data and then Spark ML for preparation and training, the InAccel FPGA cluster manager is used to offload the specific ML functions on the Xilinx’s Alveo card and speedup the ML training of the data.
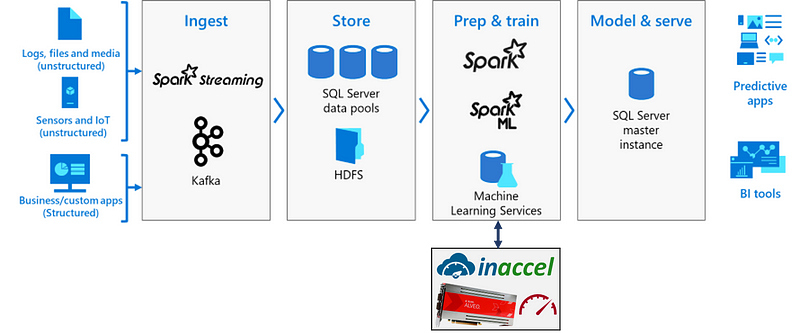
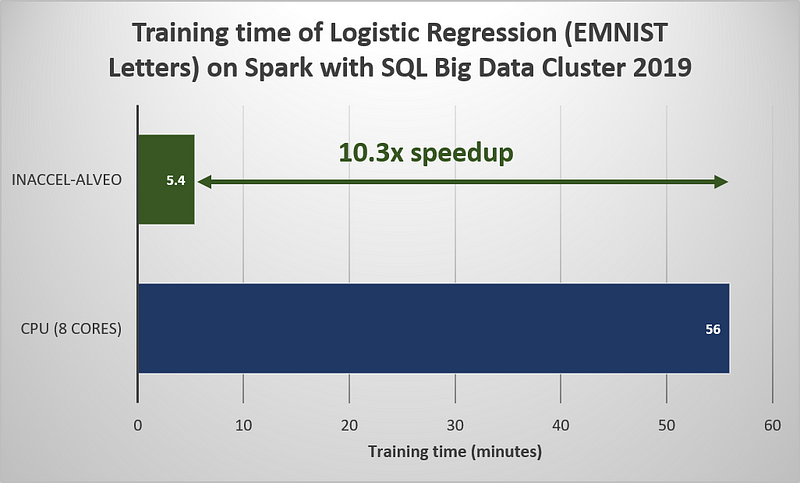
In the case of a simple example using MNIST (24GB), the proposed solution managed to achieve around 10.3x speedup compared to a CPU-only execution. In this case we used a notebook in Azure Data Studio and the ML training was offloaded to the Alveo cards using the InAccel ML IP cores and the InAccel FPGA resource manager. In this benchmark we compare 1 Alveo U200 card with 8 cores (CPU).
Concluding, at InAccel we aim at seamless acceleration of Spark over Microsoft SQL Server Big Data Cluster. With InAccel FPGA cluster manager you can speedup significantly the Spark ML applications integrated with SQL 2019 BDC