
AMD’s (AMD) $35 billion deal to acquire Xilinx (XLNX) has been recently approved by shareholders of both chipmakers. However there are several cases in the domain of deep learning that GPUs are considered more powerful than FPGAs. Then, why AMD decided to acquire Xilinx for $35 billion instead of further advancing its own GPUs? Further investing and developing on GPUs would also help compete the rising NVIDIA especially in the domain of data center where NVIDIA seems to have very ambitious plans.
It is true that in many cases GPUs can provide much better performance for some applications. For the Billion dollar market of deep learning, GPUs can provide unmatched performance in the cases of the training (that take place only once for each DL model and it can takes several days or even weeks). In the case of DL inference (i.e. classification of images) GPUs also provide tremendous performance (i.e. in terms of image throughput this is measured in frames per second). MLCommons provides a widely accepted benchmark for a fair comparison between several computing platform for data centers, mobile computing and edge applications. In the latest version of MLCommons, GPUs seemed to prevail in most categories in terms of throughput.
However, in many applications other requirements may be more important that the raw processing power. For example in mobile or embedded applications the energy efficiency (processing power/Watt) is more important especially when the devices is powered by batteries. Also in many edge devices or embedded systems the latency is also mission critical. In that cases, FPGAs, seem to have a competitive advantage as they offer very low latency an better energy efficiency. Especially the new FPGAs coming from Intel (S10 NG) and Xilinx Versal that integrate specially designed AI engines seems to provide a great combination of high throughput (especially on low batch size), low latency and high energy efficiency.

However, there are still cases where GPUs can provide better performance especially when we talk for large batch sizes. So going back to the question, why AMD would spend this amount of money for FPGAs?
The answer may come from the recent adoption of FPGAs in the data centers. MS Azure was one of the first cloud vendors that adopted FPGAs for accelerating it’s own applications. Project Catapult was really novel as the first commercial deployment of FPGAs in the data centers. Configurable Cloud architecture placed a layer of reconfigurable logic (FPGAs) between the network switches and the servers, enabling network flows to be “programmably transformed at line rate, enabling acceleration of local applications running on the server, and enabling the FPGAs to communicate directly, at datacenter scale, to harvest remote FPGAs unused by their local servers”. For example MS could accelerate the Bing web search ranking using the FPGAs in the servers.

Recently, Azure announced also the utilization of FPGA for Apache Spark in Azure Synapse. The data formats CSV, JSON and Parquet account for 90% of the customers’ workloads. Parsing the CSV and JSON data formats is very CPU intensive; often 70% to 80% of the query. So, MS Azure accelerated CSV parsing using FPGAs. The FPGA parser reads CSV data, parses it, and generates a VStream formatted binary data whose format is close to Apache Spark internal row format which is Tungsten. The internal raw performance of CSV parser at FPGA level is 8GB/sec, although it’s not possible to get all of that in end to end application currently. That way they managed to improve significantly the performance of Apache Spark. FPGAs can also be used to speedup the machine learning of Spark applications.
AWS was the first cloud vendor that announced the availability of FPGAs available to the end users back in 2017; called f1 instances. FPGA developers could also upload their design into the AWS marketplace. Recently, AWS announced the utilization of FPGAs on Redshift AQUA. The FPGA hardware does dataset filtering and aggregation. Filtering removes unwanted information from a data set to create a sub-set. Aggregating provides summing, counts, average values and so forth of records in a data set. The result is that less data is sent to the Redshift cluster. The cluster has to do less work on it because of the pre-processing, and can offload certain sub-query processing to the AQUA nodes.
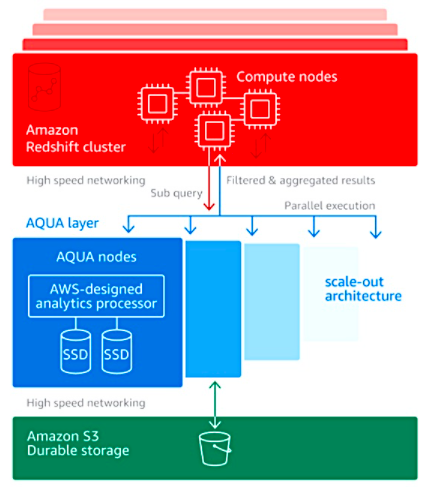
So it seems the FPGAs are keep increasing their utilization on application acceleration in data centers. But how FPGAs could be utilized not only in special cases but also in many other applications.
The key is the simpler FPGA deployment, seamless scaling and automatic resource management. GPUs provide a rich ecosystem of tools and methodologies for easy deployment, scaling and resource management (i.e. run.ai). Until now, FPGA deployment was still challenging as users had to get familiar with the technology of FPGAs (bitstream, configuration file, memory allocation, LUTs, etc.). So a key missing layer was the technology to allows software users to speedup their applications without any prior knowledge of FPGAs. This is why InAccel’s orchestrator provides a unique technology that allows anyone to utilize the power of FPGAs as easy as invoking any software function. InAccel orchestrator allows easy deployment, scaling and resource management of FPGA clusters and also easy integration with any application and framework (Spark, Ray, Keras, Scikit-learn, etc.).
For example using the power of containers, users can instantly speedup the compression applications using just a single line.
docker inaccel run -e PWD -t inaccel/apps:xilinx gzip-compression
Or they can even evaluate the performance of the accelerators online using our free demo studio:
http://compression.inaccel.com/
For more information visit InAccel website
or reach us at info@inaccel.com