FPGAs have been emerged as a powerful accelerator platform for many applications like deep neural networks, machine learning and video transcoding. FPGA vendors have released recently powerful FPGAs that can provide higher throughput, lower latency and better energy efficiency compared to GPUs. Cloud vendors have recognized the power of FPGAs and have recently adopted FPGAs as a computing resource that users can utilize. AWS was the first cloud provider that offered FPGAs as a possible computing resource for the users.
Enterprises that want to utilize the power of FPGAs are often puzzled whether it is most efficient and cost efficient to deploy FPGA on their premises or on the cloud.

Hybrid cloud is an enterprise IT strategy that involves operating certain workloads across different infrastructure environments, be it one of the major public cloud providers, a private cloud, or on-premise, typically with a homegrown orchestration layer on top[i].
This approach is particularly important to organizations with certain applications that will need to remain on-premise for the time being, such as low-latency applications on a factory floor, or those with data residency concerns. According to the RightScale State of the Cloud report 2019, hybrid cloud is the dominant enterprise strategy, with 58 percent of respondents stating that is their preferred approach. AWS for example has released Outposts. Outposts is a fully managed service that extends AWS infrastructure, AWS services, APIs, and tools to virtually any datacenter, co-location space, or on-premises facility for a consistent hybrid experience. AWS Outposts is ideal for workloads that require low latency access to on-premises systems, local data processing, or local data storage.
Until now Hybrid Cloud, was only available for typical general-purpose processors or GPUs. Companies that wanted to utilize the power of FPGAs had to select either on-premise deployment or cloud deployment due to the lack of a vendor-agnostic and platform-agnostic orchestrator. Moreover, until now there was a lack of frameworks for FPGA that offer auto-scaling allowing gradual scaling of the FPGA cluster depending on the application requirement. However, there are several cases where hybrid FPGA deployment is essential in enterprises. Especially when it comes to powerful FPGAs, where the cost can range from $3,000 to $10,000, the right provisioning of the number of FPGAs for on-prem deployment is very challenging.
Enterprise customers now have the option to adopt a hybrid deployment for their FPGA-accelerated applications. That means, that companies can purchase a small number of FPGAs deployed on-prem and if these FPGAs are overloaded, they can automatically scale it using the cloud resources. InAccel, using the unique platform-agnostic FPGA orchestration allows auto-scaling hybrid FPGA deployment in the most efficient way.
A use case on Hybrid Deployment
In this example, we show how a company can benefit from the power of FPGAs in hybrid deployment. We show an example where the application is first deployed in an Alveo cluster and when the FPGAs are overloaded then it automatically scale-out to the cloud.
Specifically, we show an example for XGBoost training. The application is first deployed on a server with 2 Alveo FPGAs (one U250 and one U280). When the number of requests for XGboost is increasing, then the cluster is automatically scaled out to include also an f1 instance in AWS with 2 more FPGAs (f1.4x). If the number of requests keeps increasing, then the cluster is further resized to include one more f1.4x instances with 2 FPGAs.
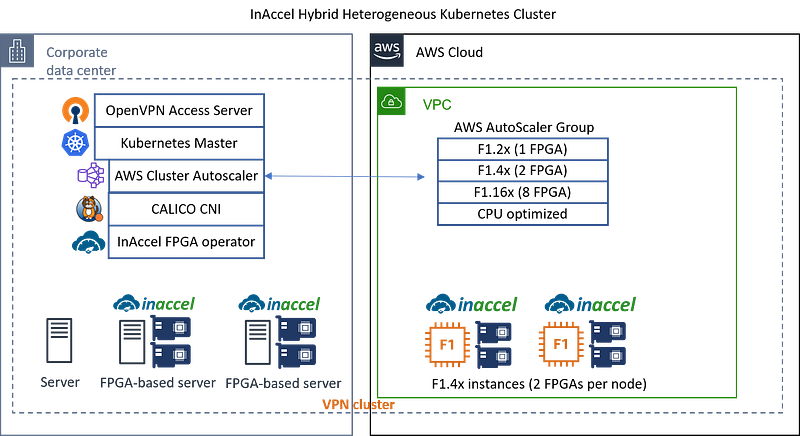
The main advantage of the InAccel orchestration is that it is platform agnostic. That means, that when a function needs to be accelerated there is no need to specify the bitstream (configuration file) or the platform that this function will be offloaded. InAccel orchestrator automatically recognizes the available resources in the cluster and it will automatically identify the right bitstream for the configuration and the deployment of the FPGAs in the hybrid cluster. That way, FPGA-based acceleration becomes easier than ever.
Companies now have the option to select as many Alveo cards for the local cluster and in case of future needs they can automatically scale-out their applications on the cloud.
InAccel Coral FPGA orchestrator is a scalable, reliable and fault-tolerant distributed acceleration system responsible for monitoring, virtualizing and orchestrating clusters of FPGAs. Coral also introduces high-level abstractions by exposing FPGAs as a single pool of accelerators to any application developer that can easily invoke through simple API calls. Coral runs as a microservice and is able to run on top of other state-of-the-art resource managers like Hadoop, YARN and Kubernetes.
InAccel Coral FPGA orchestrator allows:
- Automatic scaling to multiple FPGA cards
- Seamless resource sharing of the FPGAs from multiple users/applications
- Simple API interface for integration with framework like Scikit-learn, Keras, Jupyter, Spark and languages like Python, C/C++ and Java
It serves as a universal orchestrator for FPGA resources and acceleration requests.
The following example shows the example that have been deployed on a local server with 2 Alveo cards (U250 and U280) and 2 f1.4x instances, with 2 FPGAs per instance.
The same configuration can be used for any other application supported by Xilinx Vitis or 3rd parties IP cores, such as data analytics, databases, machine learning, neural network inference, encryption, linear algebra, and genomics.
Coral FPGA resource manager is available for free in the FPGA community. The users can request a license and can start deploying their FPGA cluster on cloud or on-prem instantly. The free version allows to deploy up to 8 FPGAs per cluster. An enterprise version is also available with unlimited number of FPGAs, detailed monitoring tool and full support.
You can see a demo on the hybrid auto-scalable FPGA deployment on the following video
https://www.youtube.com/watch?v=WVMfQrRcB0w
For more information on the hybrid deployment, you can contact InAccel at info@inaccel.com
Elias Koromilas, InAccel
Ioannis Stamelos, InAccel