FPGAs have been emerged as a high-performance computing platform that can meet the demanding AI requirements in terms of throughput, latency and energy-efficiency. FPGA vendors like Xilinx, Intel and Achronix have developed great FPGA platforms for data center and edge applications.
However a main challenge on the domain of AI/ML is the easy of deployment. Data Scientists and ML engineers care not only for high performance and fast execution but also for easy of deployment at scale. Deploying trained neural networks in applications and services can be very challenging for infrastructure managers.
InAccel provides a unique FPGA cluster manager that allows easy of deployment and scaling at production level for AI and ML applications. The FPGA manager can be used both for inference and training of ML models. Currently, it is fairly easy to offload a task on a single FPGAs. But what happens when multiple users want to deploy their applications on a cluster of FPGAs? Currently, sys admins had to manually allocate FPGAs to users resulting on low overall utilization.
InAccel has developed a unique technology that allows easy scaling and resource management of FPGAs at production level. InAccel Coral cluster resource manager performs the serialization and the dispatching of the ML tasks on the FPGA cluster automatically.
That means that users can just invoke the functions that they want to speedup without explicitly specifying in which FPGA it will be deployed and the memory transfers. The users just have to select on how many FPGAs their application will be deployed and the Coral cluster manager automatically dispatches the tasks to the available FPGA resources. That means that users can enjoy higher FPGA utilization and the faster execution of their applications. It also means easier deployment as the software developers do not need to manually dispatch the tasks to the available FPGAs. Also through the unique InAccel bitstream repository, software developers do not need any more to specify the name of the bitstream in the host code and the memory transfer making much easier the development and the invoking of the FPGAs.
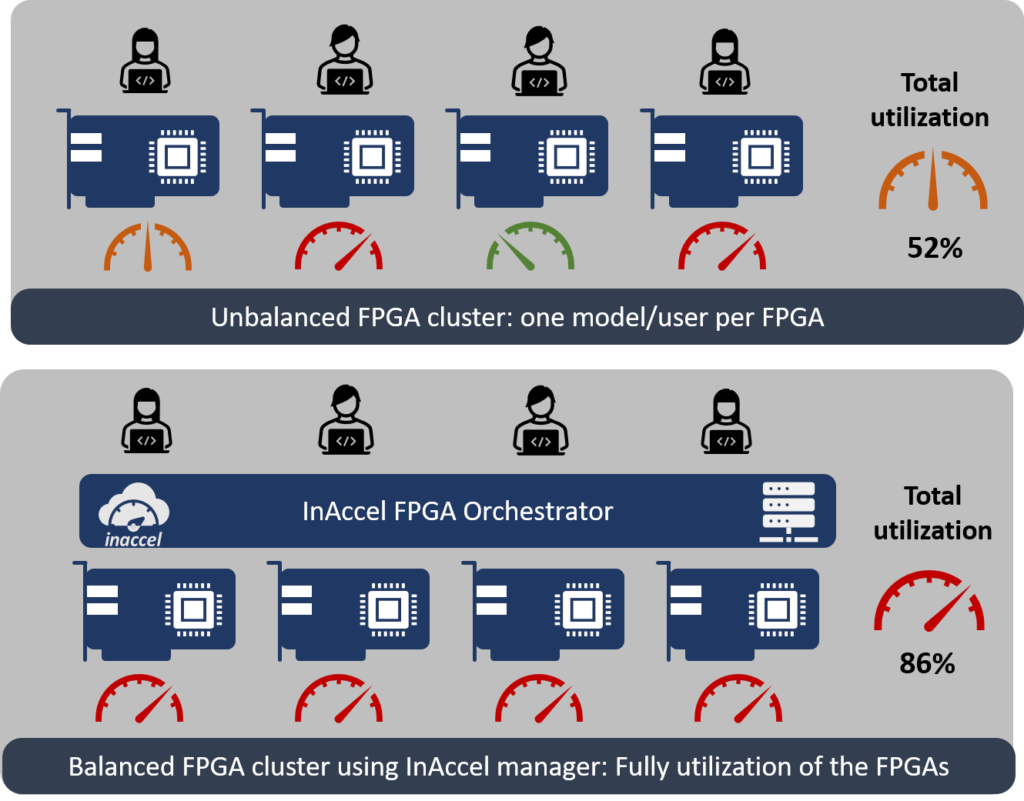
Here are the main benefits of InAccel’s Coral FPGA cluster manager.
- Designed to deploy any framework model as is: Developers can
rapidly deliver their AI-integrated applications, and IT/DevOps can
deploy retrained models without bringing down applications. Data
scientists have the freedom to choose their preferred framework
and network, and both developers and IT operators can support
these trained networks without incurring unneeded complexities. - Designed for production IT/DevOps infrastructure The InAccel Coral FPGA cluster manager is a Docker container fully compatible with Kubernetes, the container management platform for orchestration, metrics, and auto-scaling.
It also integrates with Kubeflow and Kubeflow pipelines for an end-
to-end AI workflow. It exports metrics for monitoring for better visualization of the utilization. All these integrations help IT deploy a standardized inference-in-production platform with lower complexity, higher visibility into resource utilization, and scalability. - Designed to scale and maximize FPGA utilization: InAccel Coral manager can be used to run multiple models concurrently on a single FPGA for optimal FPGA utilization. And it can easily scale to any number of servers to handle increasing inference loads for any model, eliminating
inefficient single-model-per-GPU deployment.
The figure illustrates the single-model-per-FPGA scenario. There are
4 FPGAs and 1model/user run on each FPGA. Requests for the second and fourth model peak, and the corresponding two FPGAs show very high FPGA utilization while the other FPGAs have low utilization. No more requests can be handled.
The figure below shows the same scenario with the InAccel cluster manager.
Here, each of the four FPGAs can run any — or all — of the models. When requests for the second model peak, the requests are equally balanced among all the FPGAs. This cluster easily scales to 3X higher utilization. - Designed for real-time and batch inference: There are broadly
two types of inference — real time and batch. Real-time inference
needs low latency, as end users are waiting for the results while the
inference happens. Batch inference is generally done offline and
can trade latency for high throughput. Some organizations need
both types, as that expands their use of AI in their products and
operations. InAccel coral Manager supports batch inference to
increase utilization and, at the same time, allows latency limits for
real-time inference.
Evaluate for free the InAccel cluster manager for your applications at https://inaccel.com